Generative Skill Chaining: Long-Horizon Skill Planning with Diffusion Models
CoRL 2023, Atlanta, Georgia, USA




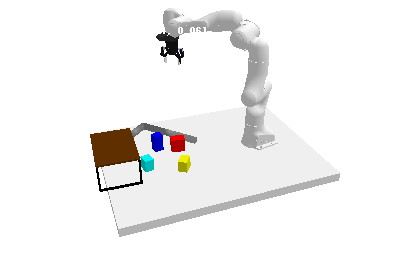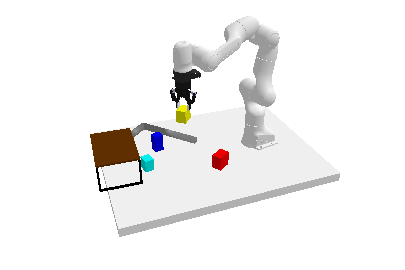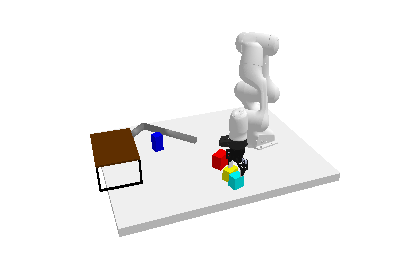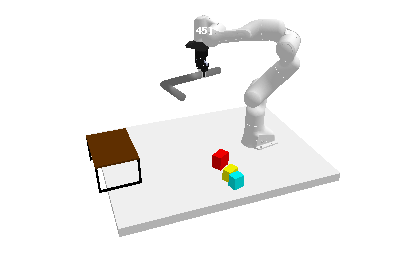

TL;DR: We introduce Generative Skill Chaining, a probabilistic framework that learns skill-centric diffusion models and composes their learned distributions to generate long-horizon plans for unseen task skeletons during inference.
Abstract
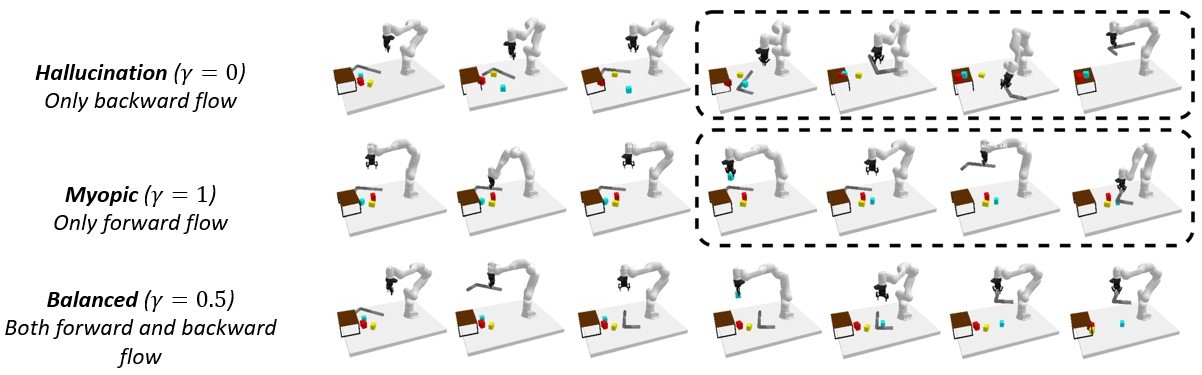
Long-horizon tasks, usually characterized by complex subtask dependencies, present a significant challenge in manipulation planning. Skill chaining is a practical approach to solving unseen tasks by combining learned skill priors. However, such methods are myopic if sequenced greedily and face scalability issues with search-based planning strategy. To address these challenges, we introduce Generative Skill Chaining (GSC), a probabilistic framework that learns skill-centric diffusion models and composes their learned distributions to generate long-horizon plans during inference. GSC samples from all skill models in parallel to efficiently solve unseen tasks while enforcing geometric constraints. We evaluate the method on various long-horizon tasks and demonstrate its capability in reasoning about action dependencies, constraint handling, and generalization, along with its ability to replan in the face of perturbations. We show results in simulation and on real robot to validate the efficiency and scalability of GSC, highlighting its potential for advancing long-horizon task planning.
Method
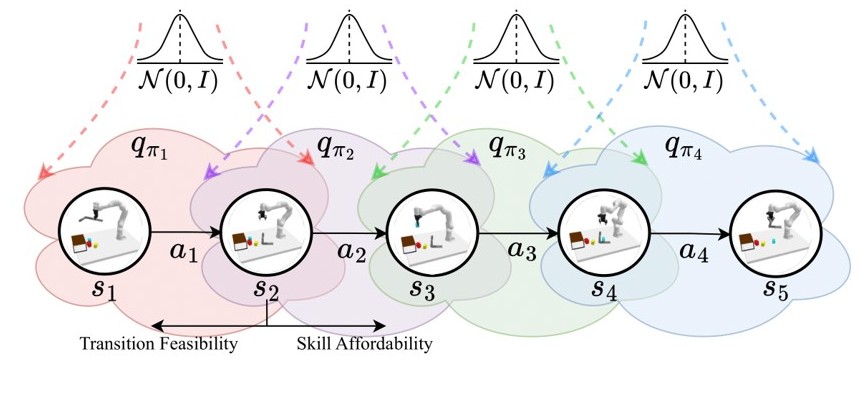
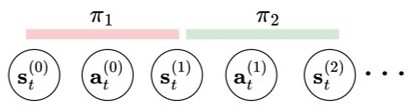
GSC is a diffusion model-based generative and compositional framework that allows direct sampling of valid skill chains given a plan skeleton. Key to our method is skill-level probabilistic generative models that capture the joint distribution of precondition - skill parameter - effect of each skill. To successfully execute a skill, the state must satisfy the precondition of the skill. We train individual diffusion models for each skill to capture this distribution.
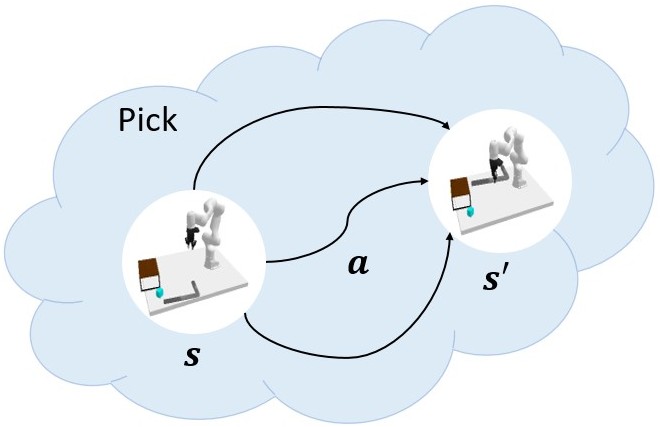
Once the skill-level distributions are captured, sampling a valid skill chain boils down to, for each skill in a plan, conditionally generating skill parameters and post-condition states that satisfy the pre-condition of the next skill, constrained by the starting state and the final goal. The critical technical challenge is to ensure that the sequence of skill parameters is achievable from the initial state (forward flow) to satisfy the long-horizon goal (backward flow) and account for additional constraints. We leverage the continuity impose by overlapping states between skills to ensure that such states ensure skill affordability for the subsequent skill and reachability (or feasibility of transition) from the state before. This phenomenon is applied while sampling parallelly from all skill-centric factored distributions to solve task-level planning as shown below.